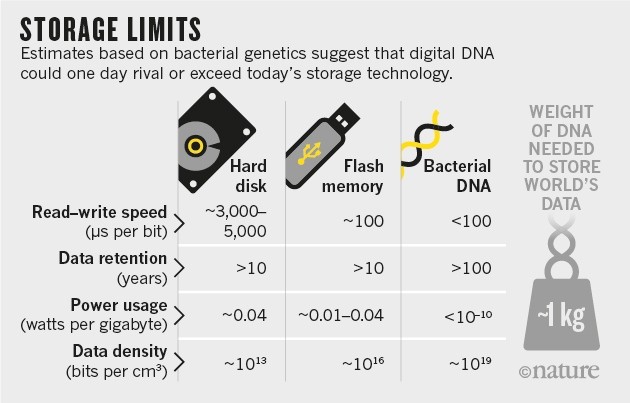
DNA: The Future of Energy-Efficient Computation and Ultra-Dense MemoryHow DNA could replace silicon to deliver sustainable, compact, and long-lasting data storage and computing power. Introduction The exponential growth in computing power and data storage demands is pushing traditional silicon-based technologies to their limits. As we approach the physical and economic boundaries of semiconductor advancements, scientists…