 International Defense Security & Technology Your trusted Source for News, Research and Analysis
International Defense Security & Technology Your trusted Source for News, Research and Analysis
Related Articles

Understanding the complex and increasingly data-intensive world around us relies on the construction of robust empirical models, i.e., representations of real, complex systems that enable decision makers to predict behaviors and answer “what-if” questions. Empirical models lie at the heart of much science (e.g., quantitative physics, material science, chemistry, biology/medicine, etc.). Basic research often aims to develop these models, which engineers and scientists can then use to develop new technologies (e.g., to fabricate new semiconductors or develop new sensors)
Today, construction of complex empirical models is largely a manual process requiring access to data scientists who perform many tasks including: 1) collaborate with subject matter experts to define a suitable modeling problem, 2) curate, select and annotate appropriate data, 3) transform, cleanse and structure data, 4) extract features from data, 5) model the data, and 6) visualize and explain the modeled outcomes. For any given empirical modeling problem, a team of subject matter experts and data scientists is typically required with expertise spanning all six of these areas to build a custom solution.
With ever more data becoming available via improved sensing and open sources, the opportunity exists to build models to speed scientific discovery, enhance Department of Defense/Intelligence Community’s intelligence, and improve United States Government logistics and workforce management, but capitalizing on this opportunity is fundamentally limited by the availability of data scientists. There are currently not enough data scientists to investigate emerging data sources that could speed scientific discovery, improve human-computer interfaces, improve United States Government (USG) logistics and workforce management, and perform other important tasks.
The Data-Driven Discovery of Models (D3M) program aims to develop automated model discovery systems that enable users with subject matter expertise but no data science background to create empirical models of real, complex processes. This capability will enable subject matter experts to create empirical models without the need for data scientists, and will increase the productivity of expert data scientists via automation.

Program Overview
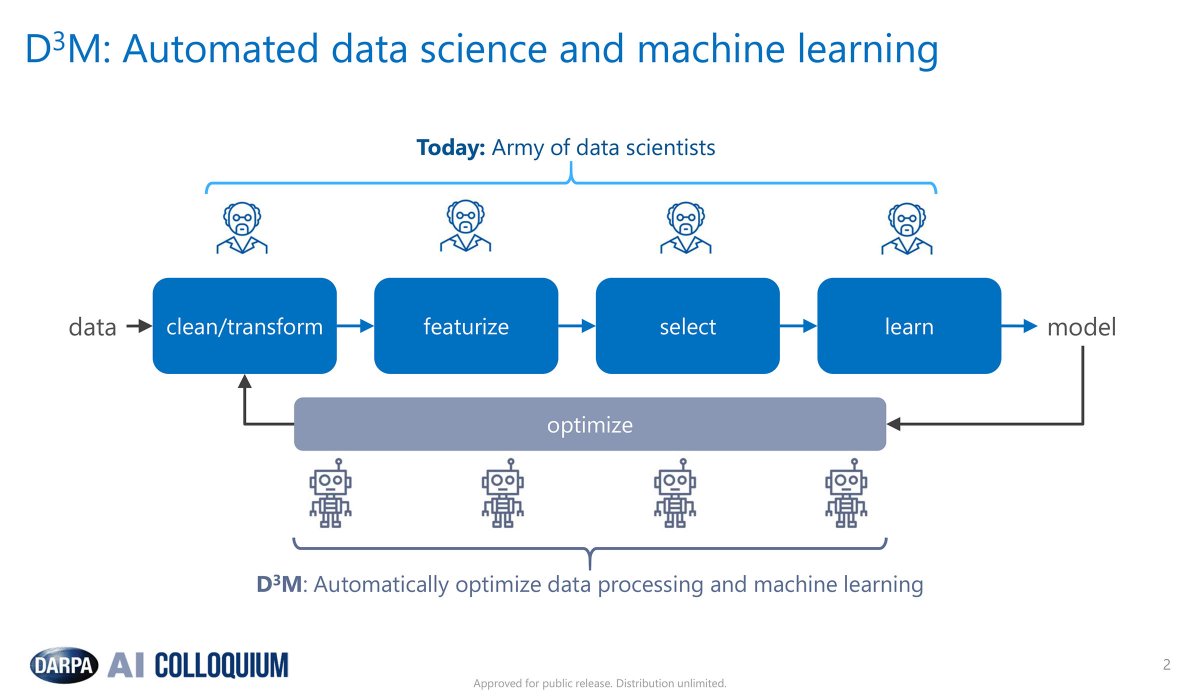
The D3M automated model discovery process, depicted in the figure, will be enabled by three key technologies to be developed in the course of the program:
- A library of selectable primitives. A discoverable archive of data modeling primitives will be developed to serve as the basic building blocks for complex modeling pipelines.
- Automated composition of complex models. Techniques will be developed for automatically selecting model primitives and for composing selected primitives into complex modeling pipelines based on user-specified data and outcome(s) of interest.
- Human-model interaction that enables curation of models by subject matter experts. A method and interface will be developed to facilitate human-model interaction that enables formal definition of modeling problems and curation of automatically constructed models by users who are not data scientists.

Automated model discovery systems developed by the D3M program will be tested on real-world problems that will progressively get harder during the course of the program. Toward the end of the program, D3M will target problems that are both unsolved and underspecified in terms of data and instances of outcomes available for modeling.
The program will be divided into two phases, of 24 months each, with evaluations structured around real world modeling problems that become increasingly more difficult as the program progresses. During the first phase of the program, performers will develop the capability to build models for a class of empirical science problems where complete data (but possibly including distractor variables) is given a priori (e.g., social and bio-science problems from repositories like dataverse, Kaggle-style business intelligence/machine learning problems, machine learning problems from OpenML). Each problem supplied during this phase will have prior expert-generated solutions. We will measure each system’s ability to recover expert-generated solutions as part of annual performer evaluations.
During the second phase, the program will work on problems that are both underspecified and unsolved (e.g., team formation in massive multi-player games, riot/disease outbreak prediction, political instability prediction, models of genetic factors for disease, etc.).
This program differs from past automated machine learning challenges such as in that preprocessing including data cleaning and feature extraction must be automated, datasets are more complex and include many types of raw data, human-model interaction must be automated, and a wide variety of datasets will be included from many application areas.
Georgia Tech, Tufts University, and Wisconsin Researchers Awarded $2.7M to Make Data Science More Accessible
Researchers at the Georgia Institute of Technology, Tufts University, and University of Wisconsin will develop new techniques to make machine learning in data science more accessible to non-data scientists under a $2.7 million grant from the Defense Advanced Research Projects Agency (DARPA) Data-Driven Discovery of Models (D3M) program.
Over the years, advances in machine learning have resulted in more complex, and more powerful, applications in information visualization. As a consequence, machine learning techniques to achieve specific insights from data have also gotten more complicated. Most require data science degrees or some formal data science training in order to use the tools that are being built. Thus, the gap between subject matter experts – international politics majors, historians, biology experts, or climatologists, for example – and the complexity of the machine learning tools used to contextualize data will continue to grow.
“Often, these experts have a wealth of knowledge about things like international affairs or cybersecurity, but they don’t have a wealth of knowledge of what it means to use machine learning model X, Y, or Z,” said Alex Endert, an assistant professor in the School of Interactive Computing at Georgia Tech, one of the four collaborators on the project. Currently, tools to adjust parameters on the data consist of buttons, control panels, dropdown menus and sliders, knobs and fields to adjust values, direct manipulations to define a machine learning model and letting it achieve the desired data.
This is less intuitive for non-data scientists, so the aim for the researchers is to move the user interaction into the visual space. Users could adjust the data within a scatter plot, for example, by zooming or panning, coloring items or generally demonstrating areas of interest inside the data. Then, they could infer how those parameters should change as a result of the exploration of the data. “If we are successful, we have the chance to bring data analysis to the public,” said primary investigator Remco Chang, an associate professor in the Tufts University Department of Computer Science. “But to get there, we will need to allow the end users to be able to intuitively ask questions about their data that can be formalized and executed in machine learning. We need to allow the user to make sense of the complex results from machine learning and help contextualize the results in the user’s domain.”
The grant, which took effect earlier this year, will fund four years of research. Other participants are Georgia Tech School of Interactive Computing Professor John Stasko, and University of Wisconsin Department of Computer Science Professor Michael Gleicher.
U Michigan Researchers Win $1.6 Million to Contribute to DARPA Machine-Learning Technique Repository
Researchers, hospitals, companies, consumers and government agencies are drowning in data that they can’t fully capitalize on. Now, a team from the University of Michigan has received $1.6 million from the Defense Advanced Research Projects Agency (DARPA) to help develop a toolkit so that even non-data-scientists can use that data to possibly answer questions and ultimately speed up the process of discovery.
The Michigan project seeks to develop algorithms that draw on techniques like machine learning for applications such as understanding video. It is one of 24 projects selected from around the country. DARPA intends to combine techniques from the projects into a central repository. “This is a visionary idea to help create a system that is intelligent about how it selects which algorithms to apply to a specific data set,” Laura Balzano, an investigator on the project and assistant professor of electrical and computer engineering at U-M, said of DARPA’s overarching project, known as Data-Driven Discovery of Models.
While the Data-Driven Discovery of Models system is expected to be able to tackle nearly any question that can be answered with a data set, one of the early problems it will address is agricultural. Given data from a farm covered in cameras and other sensors, can it predict how to optimize plant growth while limiting resources such as water and pesticides?
The Michigan project is called SPIDER: Subspace Primitives that are Interpretable and DivERse. The team, led by Jason Corso, an associate professor of electrical engineering and computer science, is developing new techniques to extract meaning from different types of data sets. Growing out of Corso and Balzano’s expertise in image processing and computer vision, this project will focus on breaking down data that has, in theory, a huge capacity for variation by identifying the features that are much less variable.
For instance, a 128-by-128 image of a face contains 16,384 pixels, but the pixels don’t vary independently from one another. In fact, the expected variations can be described by about 10 or 20 dimensions, said Corso—down from 16,384 assuming that each pixel is independent of the others. By looking at “subspaces” like this, he and Balzano simplify the problem of interpreting images and other arrays of data.
SPIDER’s contribution
It is difficult for computers to make sense of data that comes in multiple, connected flavors. For instance, video is more than just moving pictures. It’s also audio, which is crucial to understanding the context. Corso has developed a technique that converts video into text. The text is not mere captioning – rather, the system identifies what’s happening in the video and provides a written summary.
Already, the team has been developing algorithms that analyze videos of car crashes uploaded to YouTube—deducing information such as how fast the cars were going, rates of deceleration, and forces at play—to create a data set that could one day train autonomous vehicles to plan evasive maneuvers for crash prevention.
Computer vision also stumbles when images or actions differ from what it has learned. One of Corso’s new projects is looking at video from body cameras, trying to understand what goes right and wrong when police and citizens interact. They want to identify signs of agitation, indicating that the tension is escalating. Speculating, Corso suggested that agitated people might wave their arms, but different people make these gestures at different speeds. The algorithm needs to recognize the action of arm-waving, ignoring the rate of the movement.
Finally, the Michigan team aims to develop new “clustering” techniques to segment large data sets into meaningful categories. Balzano has used clustering for face recognition, looking at how one pixel relates to others in the image. This technique can identify a face in bright or shadowed conditions, or even when part of it is hidden.
Balzano’s algorithms take advice from humans, similar to photo-organizing software. The human is asked to compare two faces to determine if they are the same, and this information goes into the system. Balzano’s group enabled the computer to correctly find all matches after recording 100 human comparisons, down from 1,000.
DARPA’s overarching project
The techniques that the DARPA-sponsored teams develop will go into a central repository, open to researchers. This repository will assemble these algorithms into models that use vastly different types of data sets to make predictions and draw conclusions. Already, a few thousand methods from currently available software systems are being added to the repository. “You always need new algorithms and new ways of modeling data,” said Balzano. “This project puts them into a system.”
Once all of the algorithms are in the database, an automated software system will try them out to see which work best on a given problem. Then, they will use machine learning techniques to assemble them into models that can propose solutions, such as whether two faces are the same or not. Finally, humans will be called in to interact with these assembling systems to provide insight and hints about the information in order to get the best outcomes. “The insights of the human expert in the loop are invaluable,” said Corso. “Humans have a great way of building bridges automatically.”
SCS Researchers Top Leaderboard in DARPA AutoML Evaluations
Researchers led by Saswati Ray, a senior research analyst in the School of Computer Science’s Auton Lab, have once again received top scores among teams participating in the Defense Advanced Research Project Agency’s program for building automated machine learning (AutoML) systems.
The Data-Driven Discovery of Models (D3M) program seeks to automate the process of building predictive models for complex systems, with the goal of speeding scientific discovery by enabling subject matter experts to build models with little or no help from data scientists. More than 10 teams, most from academic centers, participate. Four or five times each year, DARPA evaluates each team’s algorithm for building this AutoML pipeline by applying it to several previously unseen problems.
Over the last two years, Ray’s algorithms have consistently outscored all others in these tests, even though her code is shared with the other teams after each evaluation. “She remains the reigning Queen of AutoML,” said Artur Dubrawski, research professor of computer science and director of the Auton Lab. “We’ve gotten used to Saswati doing this, but to continue being number one in such a tight contest for so long is like winning seven or eight Stanley Cups or Super Bowls in a row.”
In the latest evaluation, a sub-team including the Auton Lab’s Jarod Wang, Cristian Challu and Kin Gutierrez also topped the leader board in a component category — building collections of “primitives” for performing ML-related tasks such as data conditioning/preprocessing or classification. Their new time series forecasting algorithm pushed their collection to the top spot, Dubrawski said.
D3M Project at NYU VIDA Center
The Data-Driven Discovery of Models (D3M) program aims to develop automated model discovery systems that enable users with subject matter expertise but no data science background to create empirical models of real, complex processes. At the NYU VIDA Center we address three important challenges in automating machine learning: pipeline synthesis, model understanding/curation and data augmentation.
ALPHAD3M
AlphaD3M is an AutoML system that automatically searches for models and derives end-to-end pipelines that read, pre-process the data, and train the model. AlphaD3M uses deep learning to learn how to incrementally construct these pipelines. The process progresses by self play with iterative self improvement.
VISUS
Visus is a system designed to support the model building process and curation of ML data processing pipelines generated by AutoML systems. Visus also integrates visual analytics techniques and allows users to perform interactive data augmentation and visual model selection.
AUCTUS
Auctus automatically discovers datasets on the Web and, different from existing dataset search engines, infers consistent metadata for indexing and supports join and union search queries. Auctus is already being used in a real deployment environment to improve the performance of machine learning models.
References and Resources also include:
https://ai.engin.umich.edu/stories/1-6m-toward-artificial-intelligence-for-data-science