Digital battlefields, hybrid warfare, and the future of threat intelligence
IDST Intelligence Briefings
(Latest Security & Cyber Videos)
Why This Magazine Exists
Security, Cyber & Counter-Threats examines the evolving landscape of modern security in an era defined by digital conflict, hybrid warfare, and persistent global threats.
From cyber operations, information warfare, and intelligence-driven defense to counter-terrorism, internal security, and emerging threat vectors, this magazine provides strategic analysis, technical insight, and policy-relevant perspectives for decision-makers, practitioners, and researchers navigating an increasingly contested security environment.
What We Track
- Cyber warfare & cyber defense
- Information operations & influence campaigns
- National security threat assessments
- Emerging digital and hybrid warfare doctrines
- Critical infrastructure & cyber resilience
Latest Analysis & Intelligence
-

UAV EO/IR Payloads: From Passive Cameras to Autonomous Kill Chains (2026 Update)
Introduction: The Sensor Race Inside the Drone Revolution The global UAV market is expanding rapidly, but the most decisive competition is no longer over airframes—it is over payloads. In modern unmanned systems, the sensor often matters more than the platform carrying it. Among all payload categories, Electro-Optical/Infrared (EO/IR) systems remain the most widely fielded, combat-proven,…
-

Cracking the Code of Life: The Evolution of Human Genome Sequencing from Blueprint to AI-Powered Precision
For decades, the human genome has captivated scientists as the ultimate blueprint of life—an intricate code written in molecular letters that determines everything from eye color to susceptibility to disease. The quest to read, understand, and interpret this code has evolved from an ambitious international scientific effort into an era of AI-powered genomic medicine, poised…
-

UAV SAR Payloads: Seeing Through Darkness, Smoke, and Deception
Introduction The global UAV payload market is accelerating toward nearly $24 billion by 2030, but among all payload categories, Synthetic Aperture Radar (SAR) is emerging as one of the most strategically important growth segments. Once limited to large and expensive MALE and HALE unmanned aircraft used for strategic intelligence missions, radar miniaturization, improved processors, lighter…
-

The Atomic Architects: How AI-Driven Nanotechnology Is Redefining Materials, Manufacturing, and Strategic Power
For centuries, technological progress has been defined by humanity’s ability to manipulate matter—first at the macroscopic scale, then at the microscopic level, and now at the atomic frontier. Today, a profound transformation is underway: the convergence of artificial intelligence and nanotechnology is enabling the controlled design and assembly of matter at the level of individual…
-
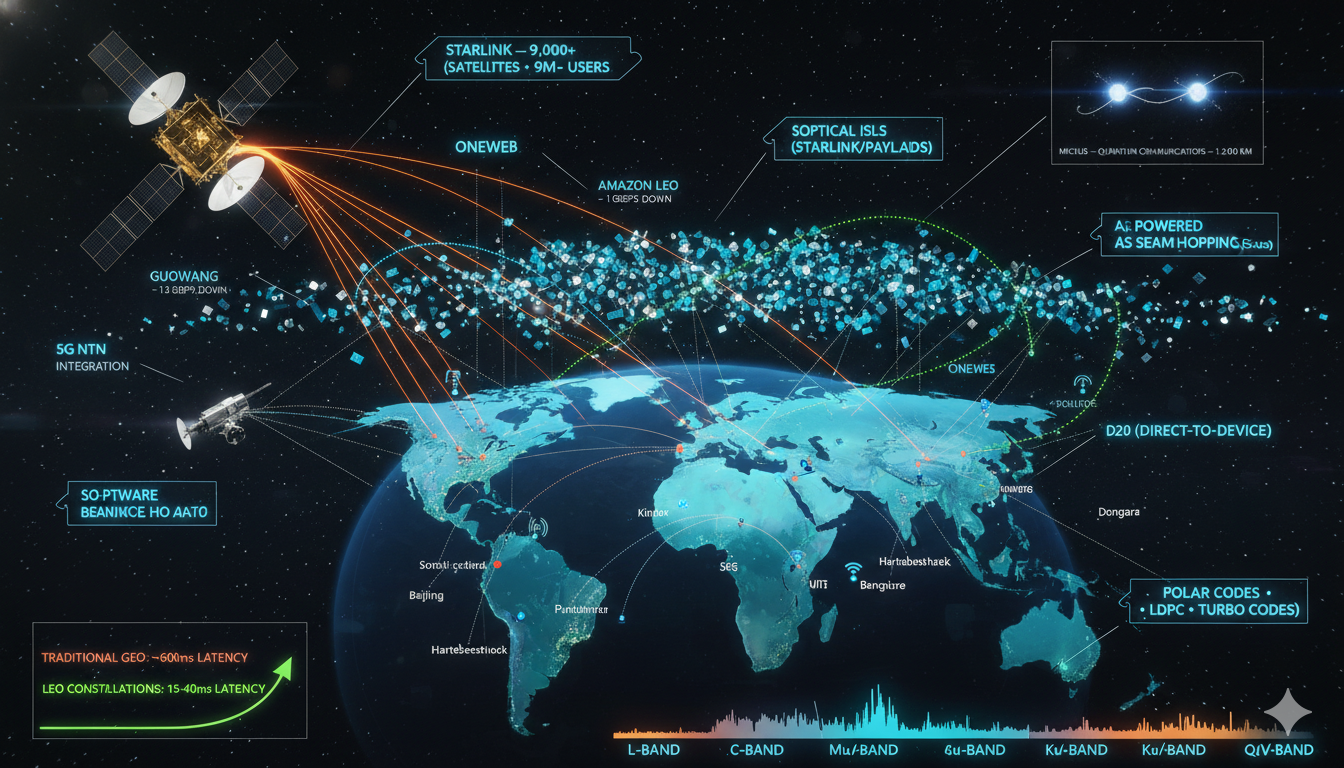
Satellite Communications Technologies and Trends: 2026 Update
From GEO Dominance to AI-Native, Quantum-Ready, Multi-Orbit Networks Introduction: SatCom Becomes Critical Digital Infrastructure Satellite communications is undergoing a structural transformation from a specialized communications medium into a foundational layer of the global digital ecosystem. What was once dominated by a limited number of geostationary satellites is now evolving into a densely populated, multi-orbit, software-defined…
-

The Fifth Industrial Revolution: Where Humans and Intelligent Machines Co-Create the Future
For more than a decade, global technological discourse has been dominated by the concept of the Fourth Industrial Revolution—an era defined by digital connectivity, cloud computing, artificial intelligence, and the fusion of technologies blurring the boundaries between the physical, digital, and biological worlds. Yet as the 2020s progress, a new paradigm is emerging from the…
-

Software-Defined Radios (SDRs): The Flexible Core of Next-Generation Satellite Ground Stations
Transforming Ground Segment Architectures in the Era of LEO Mega-Constellations and Software-Defined Space Systems Executive Overview The rapid transition from a relatively static, geostationary satellite architecture to highly dynamic, multi-orbit constellations has fundamentally reshaped the requirements of the satellite ground segment. At the center of this transformation is the emergence of Software-Defined Radio (SDR), which…
STRATEGIC SUB-MAGAZINES
Modern military power emerges from the interaction of platforms, people, doctrine, and integration across domains. The Defense & Military Systems magazine is structured into focused sub-magazines that examine how combat capability is built, sustained, and employed across air, land, sea, weapons, and human systems.
Cyber & Information Warfare
Industrial outcomes are shaped as much by incentives, policy, and market structure as by engineering. Price signals, investment cycles, and regulatory frameworks quietly determine which technologies scale, stagnate, or fail.
This sub-magazine examines how markets behave under strategic pressure—where capital flows, how demand signals distort decisions, and why some industries adapt faster than others.
Explore the Cyber & Information Warfare Sub-Magazine →
Security & Threat Management
Modern security is defined by persistence, coordination, and anticipation. This sub-magazine focuses on how threats are identified, mitigated, and managed across institutions, infrastructures, and societies.
Explore the Security & Threat Management Sub-Magazine →