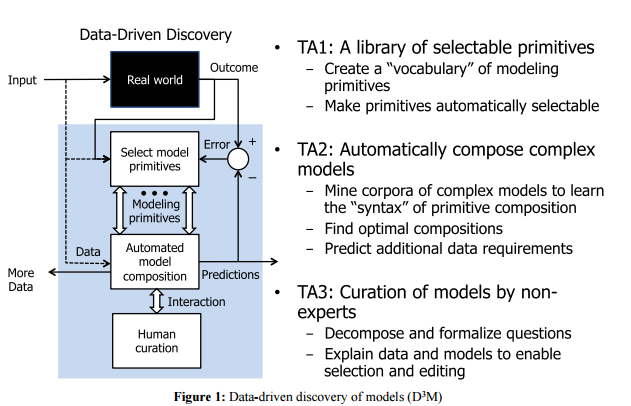
Understanding the complex and increasingly data-intensive world around us relies on the construction of robust empirical models, i.e., representations of real, complex systems that enable decision makers to predict behaviors and answer “what-if” questions. Empirical models lie at the heart of much science (e.g., quantitative physics, material science, chemistry, biology/medicine, etc.). Basic research often aims…