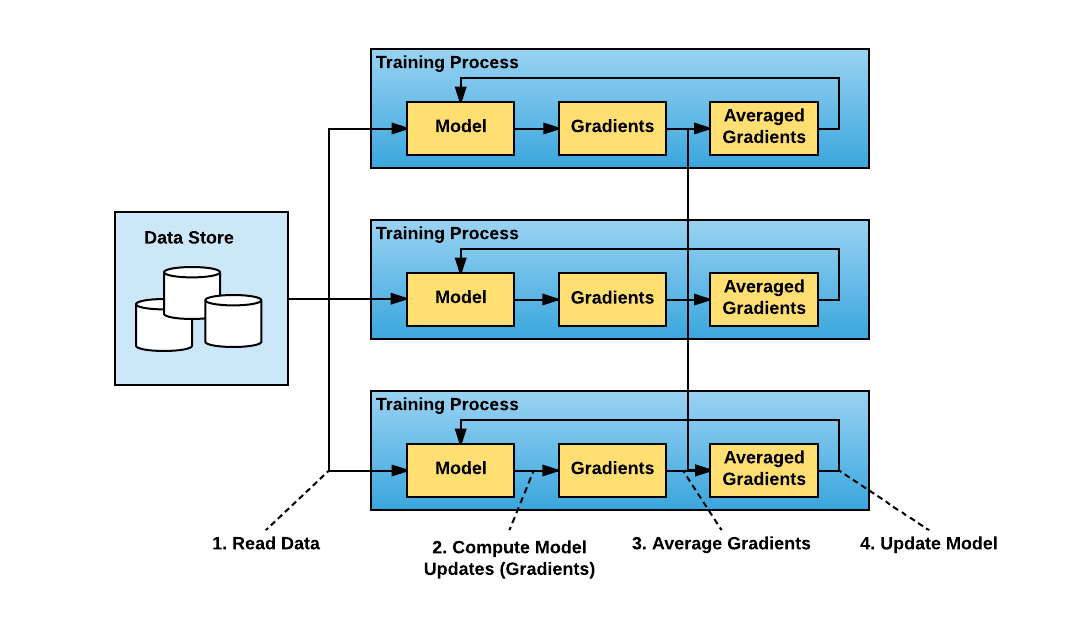
Machine learning is a set of algorithms which are modeled after the human brain and are designed to take in large amounts of data and recognize patterns. What sets them apart is not just how fast they can analyze data, but the fact that they can actually learn and improve upon their results as they…