Engineers regularly use high-fidelity simulations to create robust designs in complex domains such as aeronautics, automobiles, and integrated circuits. In contrast, robust design remains elusive in domains such as synthetic biology, neuro-computation, and polymer chemistry due to the lack of high-fidelity models. DARPA’s Synergistic Discovery and Design (SD2) program aims to develop data-driven methods and tools to accelerate scientific discovery and robust design in domains that lack complete models.
Examples of complex systems where inventors lack complete scientific models to support their design efforts include biological systems that have millions of protein-metabolite interactions, neuro-processes that require computations across billions of neurons, and advanced materials influenced by millions of monomer-protein combinations.
These systems are part of domains that exhibit millions of unpredictable, interacting components for which robust models do not exist, and internal states are often only partially observable. In such domains, small perturbations in the environment can lead to unexpected design failures, and the number of engineering variables required to characterize stable operational envelopes remains unknown.
While domain experts remain geographically dispersed, they collectively analyze hundreds of terabytes of data to build models and refine designs. However, manually-intensive analysis of small datasets remains inefficient and often yields unreproducible results. In response, researchers have begun to outsource high-throughput experiments to automated labs and randomly search constrained parameter spaces for robust designs. However, these random search-based approaches work best with small parameter spaces and provide no insight into why some designs succeed and others fail.
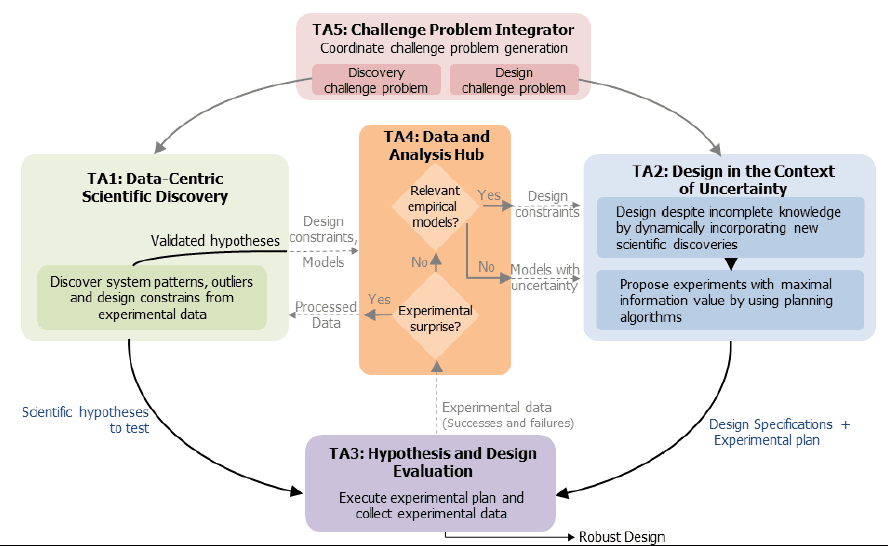
SD2 will address the problem of design in domains that lack complete models by discovering models and refining designs via methods that extract information from data at petabyte scale. SD2 aims to develop data-driven methods to automatically discover models and refine designs in parallel at scale. To ensure realism, challenge problems drawn from cutting edge domains will drive the development of SD2 methods. By the end of the program, SD2 plans to provide new data-driven methods to accelerate discovery and design and create a cloud-based open data exchange for research communities in complex domains.
Initially, SD2 will use challenge problems from synthetic biology for program wide evaluation. Synthetic biology provides a compelling driving application domain for the following reasons:
(1) full characterization of the underlying biology requires complex mechanistic formalisms at a scale that defies manual discovery; (2) advances in the last 20 years have enabled scientists to more efficiently modify organisms in more complex and targeted ways; (3) terabytes of high quality synthetic biology data can be generated in a few days; and (4) design of synthetic biology systems remains a very laborious process that typically involves heuristic knowledge, brute force, and trial and error approaches.